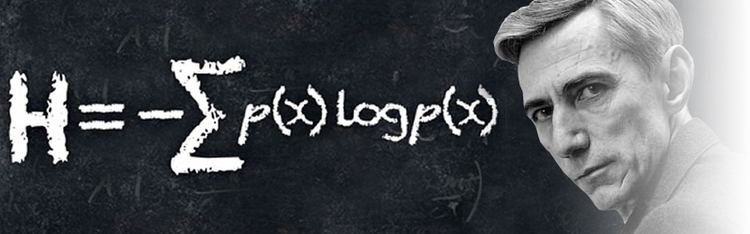
Information Theory and Coding
The equation in the image above was published in the 1949 book "The Mathematical Theory of Communication", co-written by Claude Shannon and Warren Weaver. An elegant way to work out how efficient a code could be, it turned "information" from a vague word related to how much someone knew about something into a precise mathematical unit that could be measured, manipulated and transmitted. It was the start of the science of "information theory", a set of ideas that has allowed us to build the internet, digital computers and telecommunications systems. When anyone talks about the information revolution of the last few decades, it is Shannon's idea of the information that they are talking about. [ref]
We at SPCRC are working on latest developments in coding theory which would have broad applications in the future signal processing and communication domain.
In a distributed storage system (DSS), data is required to be stored reliably and efficiently across nodes in a network, where the nodes themselves are failure-prone. Metrics of interest in a distributed storage system are (i) Storage overhead (ii) Reliability (iii) Number of nodes contacted for the repair of a failed node termed the repair degree (iv) Total amount of data downloaded to repair a failed node termed repair bandwidth. It is of interest to have, with a certain degree of reliability, low storage overhead, low repair degree and low repair bandwidth. DSS found in practice, including Windows Azure Storage and the Hadoop-based systems used in Facebook and Yahoo.
The next century is popularly being called as the "Age of biology", for that is one of the most important frontiers that has opened up ever since the discovery of the double helix structure of the DNA molecule. Further scientific developments have now enabled the storage of information in DNA. While DNA storage has the advantage of longevity and density, current high-fidelity DNA storage techniques remain extremely cost-ineffective. Error-Correcting Codes for DNA storage can be used effectively in conjunction with low-fidelity (and thus low cost) DNA storage techniques to still retain the correctness of the original information.
The future wireless traffic will be dominated by video(ex Netflix, YouTube) which is generated well ahead of user demands. During peak traffic time networks are congested but underutilised during off-peak time. Hence the available spectrum is not utilised properly. Coded caching is a technique proposed to shift the network traffic from peak to off-peak time by utilising the cache memory available at users. In other words, coded caching replaces the expensive bandwidth with cost-effective memory.
Data analytics platforms today handle huge quantities of data and want to perform some computations on them. To manage the load while reducing the latency of computation, this data is processed in a distributed and parallel method by distributing the data to several worker nodes, each of which individually processes the data in parallel, and ultimately combining this sub-results into the complete result. Implementing this distributed computation technique in parallel presents many challenges, such as managing the communications between the nodes, handling worker nodes which complete their sub-jobs much slower than others (such slow nodes are known as straggler nodes). Coding theory has shown promise in overcoming these challenges. Codes for distributed computing (CDCs) would be used to encode the data before splitting it to the worker nodes in such a way that straggler nodes do not affect the final computation latency. Similarly, the communication between the nodes of the cluster would also be coded, to exploit the existence of parts of data in the memory of the nodes themselves. This is known as Coded Communication for Distributed Computing. We seek to develop new and effective schemes for these classes of problems in Distributed Computing.